転写
- 転写とは?
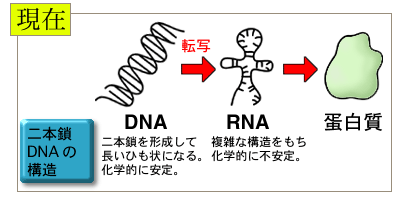
遺伝子DNAの情報をRNAに写すこと。

遺伝子の設計図集から一つの部品の設計図を写す。

写した設計図を職人さんに見せて部品(蛋白質)を作ってもらう。- DNAとRNAにはどんな風に書かれているか?
遺伝子DNAの情報をRNAに写すこと。
 遺伝子の設計図集から一つの部品の設計図を写す
遺伝子の設計図集から一つの部品の設計図を写す 写した設計図を職人さんに見せて部品(蛋白質)を作ってもらう
写した設計図を職人さんに見せて部品(蛋白質)を作ってもらう文責:西嶋仁 柴原慶一
- なぜ直接DNAから蛋白質を作らないのか?
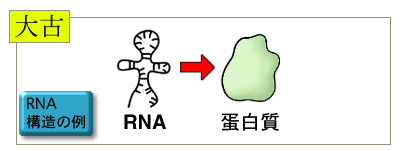
太古の昔はRNAが遺伝子を作っていたと考えられています。遺伝情報の量が増加し複雑になると、RNAより安定なDNA、それもより安定な二本鎖DNAに情報を保存するようになり、転写が始まったと考えられています。またこのように一段階増やすことによって、より複雑な調節が可能になりました。
- 転写をおこなう分子とそのしくみは?
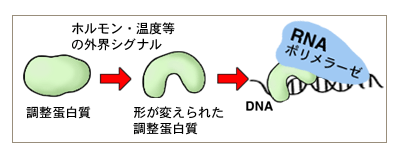
DNA情報の読み取り装置は、RNAポリメラーゼです。外界からの「読みとれ命令」は、転写調節蛋白質に、低分子化合物の結合や化学修飾によって伝えられ、RNAポリメラーゼと共にDNAにくっついたり、RNAポリメラーゼがDNAにくっつくのを妨げたりして、読みとりを調節しています。
- 転写の始まりと終わりはどのようにして決まっているの?
DNAの上には、転写調節蛋白質と協力して、RNAポリメラーゼがRNA合成を開始できるプロモーターと呼ばれる部分が1つの遺伝子に1つ以上あります。プロモーターは特別なATGCの配列をもっていて、RNAポリメラーゼは転写調節蛋白質とかかわりあいながらこの配列を読みます。
RNAが合成され、定まった長さになると、RNA上の配列やDNA上の配列をRNAポリメラーゼ達が読み取ってそこでRNA合成を終了します。この場所をターミネータといいます。
転写調節
- はじめに
バクテリアで数千、高等動物では数万とも数十万ともいわれる遺伝子のセットのうち、どれを、いつ、どこで、どの程度発現させるかは、生物にとってもっとも重要な戦略のひとつである。外界からのさまざまな刺激や生物が生まれもつ発生、分化、増殖、加齢などのプログラムによって、個々の遺伝子の転写が時間的、空間的に調節される。転写調節についての研究は、原核生物、真核生物のいずれの分野においても、ここ数年の間に大きな変化を見せている。それまでの転写因子一辺倒の研究から、転写装置であるRNAポリメラーゼ本体、基本転写因子群などにも目が向けられるようになり、調節の分子機構の解明へとわずかながら近づいてきた。別の見方をすれば、転写因子とDNAとのタンパク質—DNA相互作用ばかりでなく、さまざまなタンパク質因子間のタンパク質—タンパク質相互作用(相互作用ネットワーク)によって転写調節を理解しようという流れでもある。このセクションでは、転写調節、なかでも転写開始時における正の調節について、おもに構造生物学の視点から概観することにする。
藤田信之著「遺伝子の構造生物学」(共立出版)pp92-103より引用
- 転写調節の主役たち
転写調節の一方の主役はいうまでもなく転写因子である。星の数ほどある転写因子は、それぞれに特徴的な塩基配列を認識してDNAに結合し、直接または間接に転写装置(真核生物における基本転写因子群を含む)にはたらきかけて、転写を正または負に調節する。転写因子は構造解析の重要なターゲットであったが、とくに90年代にはいってからは、多くの転写因子についてDNAとの複合体の構造が明らかにされ、その数は現在では優に50種を超えている。これによって、タンパク質による特異的なDNA認識の機構が明らかにされてきた。この点については第3章に詳しく述べられている。
転写調節のもう一方の主役は転写装置である。転写因子が調節の多様性を支えるものであるとすれば、転写装置はさまざまな転写因子からのシグナルを集約し、最終的な転写レベルを決定する情報センターとしての役割を担っている。単純なRNA合成マシンというイメージからはほど遠い新しい転写装置像である。これこそが最近の転写調節研究の流れを象徴するものといってよいだろう。
原核生物においては転写装置はRNAポリメラーゼと同義である(ただし転写の伸長や終結の過程まで含めて考えるとこの定義は必ずしも正しくない)。原核生物のRNAポリメラーゼは、古細菌やラン藻などの例外を除けば、4種類、5個のサブユニットからなるα2ββ'σの構造をとっている。真核生物には3種類のRNAポリメラーゼ(I,II,III)が存在し、そのうちRNAポリメラーゼIIがmRNAの転写を行う。RNAポリメラーゼIIは少なくとも10種類のサブユニットをもつことに加え、さまざまな調節因子を抱え込んださらに巨大な複合体(ホロ酵素)の存在も報告されているなど、分子的な実体は必ずしも明らかではない。藤田信之著「遺伝子の構造生物学」(共立出版)pp92-103より引用
- プロモーター認識におけるタンパク質-DNA相互作用
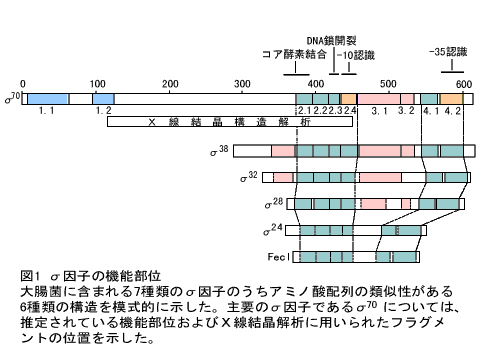
転写開始複合体形成時における特異的なDNA認識(プロモーター認識)の機構がしだいに明らかにされつつある。原核生物の大多数のプロモーターは、転写開始点の上流約10塩基と35塩基の位置によく似た配列(-10配列および-35配列と呼ばれる)をもつ。これらの配列がRNAポリメラーゼσサブユニット(σ因子:Key Word参照)のそれぞれ特定の領域(領域2.4および領域4.2)によって認識されることが遺伝学的、生化学的な解析から明らかとなった(図1)。また、転写を開始するためにはプロモーター配列を正しく認識することに加えて、転写開始点付近のDNA2本鎖を1本鎖にほどく必要があるが、σの領域2.3にある芳香族アミノ酸が、DNA塩基とのスタッキングによってDNAの1本鎖状態を安定化すると考えられている。このように転写開始反応において中心的な役割を果たすσであるが、多くの研究者の努力にもかかわらず、構造解析は進んでいない。ようやく1996年になって、大腸菌の主要σ因子であるσ70の部分構造がX線結晶構造解析によって明らかにされた。コア酵素への結合や-10配列認識の一端をうかがわせるものではあったが、多くの問題が未解決のままである。
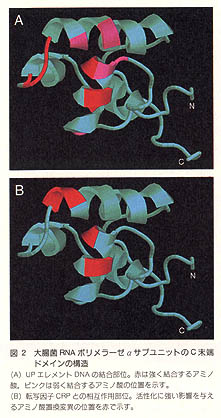
発現レベルの高い一部のプロモーターでは、-35配列よりさらに上流10~30塩基の位置にATに富んだ配列が存在し、これによって転写活性が数十倍に増強されることが知られている。-10配列、-35配列に続く第三のプロモーター構成要素と考えることもできる。UPエレメントと呼ばれるこの配列を認識するのはσではなく、αサブユニットのC末端のドメインである。このドメインの立体構造がNMRによって明らかにされた。4本のαヘリックスからなる構造は、他のどのDNA結合タンパク質とも似ていない新しいものであった。DNAとの複合体の構造は明らかではないが、UPエレメントDNAの添加によるNMRシグナルの変化から、どのアミノ酸残基が物理的にDNAと接触しているかを推測することができる。こうしてマップされたアミノ酸残基(図2A)はドメインの片側の表面に集中しており、この部分がDNAとの特異的、非特異的な結合に関与しているものと思われる。なお、αサブユニットのC末端ドメインは多くの転写因子とのタンパク質-タンパク質相互作用にも関与しているが、この点については後述する。
真核生物のRNAポリメラーゼIIによって転写される遺伝子は、多くの場合転写開始点の上流にTATAという配列をもち、これがひとつのプロモーター構成要素となっている。原核生物の場合と決定的に異なるのは、TATA配列を認識するのがRNAポリメラーゼ自身ではなく、TFIIDと呼ばれる基本転写因子のひとつである点である。TFIIDはそれ自身が10種類近くのタンパク質からなる巨大な複合体であり、実際にTATA配列に結合するのはその中のTBP(TATAボックス結合タンパク質)と呼ばれる成分である。1992年にTBPのコアドメインと呼ばれる部分の構造が、続いて1993年にはTBPとTATA配列を含むDNAとの複合体の構造が、X線結晶構造解析によって明らかにされた。巨大な転写開始複合体の中のごく一部の構造ではあったが、きれいな2回回転対称をもつ馬の鞍のような形状といい、DNA結合タンパク質としては例外的ともいえるDNAの副溝側からの塩基認識といい、結合によってDNAをするどく折り曲げている様といい、転写を研究している人たちが構造生物学への新たな期待をふくらませるのに十分なインパクトをもつものであった。
Key Word:σ因子の多様性
多くの原核生物は、栄養増殖期にはたらく主要σ因子以外に、定常期や胞子形成期にはたらくもの、ストレス時に一過的にはたらくものなど、複数のσ因子をもつ。σ因子ごとに確認するプロモーターの配列が異なり、これによって転写の包括的な調節が行われている。
藤田信之著「遺伝子の構造生物学」(共立出版)pp92-103より引用
- 転写調節におけるタンパク質-タンパク質相互作用
転写開始反応はたくさんのステップからなる複雑な反応である。まず、RNAポリメラーゼが転写開始点付近に定着する必要がある。真核生物の場合はこれに先立ってTFIIDなどの基本転写因子(Key Word参照)がDNAに結合する。次いで、転写開始点付近のDNA2本鎖が局所的に1本鎖にほどかれることにより、安定な転写開始複合体が完成する。転写が開始するとRNAポリメラーゼは構造もDNAへの結合様式も異なる伸長複合体へと変化する。原理的にはこれらのいずれの段階もが律速段階すなわち調節のターゲットとなりうる。
転写因子がどのようにして転写を活性化するのかという点に関しては、大きく分けて2つの可能性が考えられてきた。ひとつは、転写因子がDNAに結合することによって、プロモーター付近のDNAの構造や安定性が変化し、これによってRNAポリメラーゼの結合やDNA2本鎖の開裂が促進されるというものである(DNA transmission model)。とくに、転写因子の多くがプロモーターのごく近傍に結合する原核生物においては、この考えがながらく支配的であった。DNAの超らせん構造が転写に大きな影響を与えることや、転写因子の多くがDNAへの結合に伴ってDNAを湾曲させたり折り曲げたりするという事実もその背景にあった。もうひとつの可能性は、DNAに結合した転写因子が、タンパク質-タンパク質相互作用を介して、RNAポリメラーゼのDNAへの結合を助けたりRNAポリメラーゼをより活性型の構造へ変換するというものである。速度論的な解析からは両者を区別することは難しい。
後者の可能性、すなわちタンパク質-タンパク質相互作用を介した活性化(図3)がより確からしいと考えられるようになってきた背景には、いくつかの重要な発見がある。まず、転写因子の多くが、DNAへの結合に必要な構造とは別に、転写活性化に必要な構造をもつという点である。DNAへの結合はまったく正常であるにもかかわらず転写を活性化することができなくなったポジティブコントロール変異(PC変異)が原核生物のいくつかの転写因子でみつかった。λcIやCRP(cAMP Receptor Protein)などの立体構造のわかっている転写因子について見てみると、これらの変異はタンパク質表面の、DNA結合部位とは明らかに異なる位置にあることがわかった。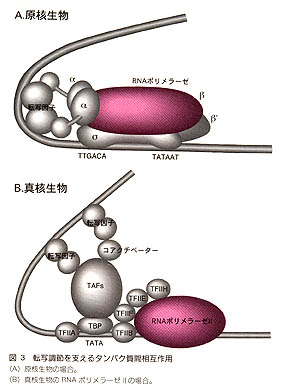
真核生物では、DNA結合ドメインと活性化ドメインがさらにはっきりと分かれている場合が多い。この場合、活性化ドメインは極端に酸性アミノ酸に片寄っていたりグルタミンに富んでいたりと、一見してそれとわかるほどの特徴的な1次構造をもっている。まったく機能の異なる転写因子の間でドメインをすげ替えることができるというPtashneらの一連の研究9)は、分子生物学者のみならず多くの構造学者をも驚嘆させた。それ自身はDNA結合能をもたず、転写因子と転写装置の間に介在して転写を調節する因子(コアクチベーター、メディエーターなどと呼ばれる)の発見も、タンパク質間相互作用の重要性を示すものであった。
一方、転写因子からの情報を受け取る側の転写装置についても、ここ数年の間に多くの重要な発見があった。まず原核生物においては、RNAポリメラーゼのαサブユニットのC末端ドメインが、多くの転写因子との相互作用に重要な役割を果たすことがわかった。このドメインを欠いた酵素は一見正常に転写を行うことができるが、調べられた中の半数以上の転写因子に対して、完全に応答能を失っていた。活性化に必須なアミノ酸残基を立体構造の上にマップしてみると、UPエレメント結合領域と微妙に重なり合う(図2B)。このことは、同じタンパク質表面が状況に応じてDNAともタンパク質とも相互作用できることを示唆している。αサブユニットのN末端ドメインとC末端ドメインを結ぶリンカー部分はきわめて柔軟にできている。この自由度の高さがαの多機能性を支えているのであろう。DNA、転写因子を含む三重複合体の構造解析が待たれる。なお、αのC末端ドメインを必要としない別の一群の転写因子が、σのC末端部分と相互作用することもわかってきた。
真核生物においては、RNAポリメラーゼ自身よりも、TFIID、TFIIBなどの基本転写因子群が転写因子やコアクチベーターと相互作用すると考えられている場合が多い。なかでも中心的な役割を果たすと考えられているのが、TBP結合因子(TAF)と総称されるTBP以外のTFIID構成タンパク質である。TBPとDNAとの複合体に続いて、TBP-DNA-TFIIBおよびTBP-DNA-TFIIA三重複合体のX線結晶構造解析が行われた。また、TAFのいくつかについても部分構造が報告されている。こうしてRNAポリメラーゼの受皿としての基本構造が明らかにされつつある。しかしながら、転写因子との相互作用の実体は依然不明のままであるし、前述のようにRNAポリメラーゼの結合以降の段階でも調節が行われている可能性は大きい。たとえば、RNAポリメラーゼIIが開始複合体から伸長複合体に移行するためには最大サブユニットのC末端がリン酸化される必要がある。Key Word:基本転写因子
原核生物ではRNAポリメラーゼ単独で基本的な転写を行うことができるが、真核生物ではこれに加えて基本転写因子と呼ばれる一群のタンパク質が必要である。RNAポリメラーゼI、II、IIIのそれぞれの系にはたらく基本転写因子があり、RNAポリメラーゼIIの系では、TFIIA、TFIIB、TFIID、TFIIE、TFIIF、TFIIHが知られている。
藤田信之著「遺伝子の構造生物学」(共立出版)pp92-103より引用
翻訳と転写後調節:転写から翻訳へ
- 生物は調節のモンスター
転写によって合成された設計図としてのRNAは、mRNA(メッセンジャーRNA)と言う形に整えられ、これを情報源にして、リボソームという分子機械が、各々の蛋白質を合成し、必要とされるところに輸送され、遺伝子発現は完了します。
転写中から転写後に起こりうるステップは、翻訳だけでなく、以下のようにさまざまなものがあります。この各段階でいろいろな調節や、複数の調節が絡み合うようになっています。面白いことに、この段階でmRNA以外にもさまざまなRNAが大活躍をします。
このように、生物は多様な調節で形成・維持されていて、「生きている」と言うことは、これらの調節が一定の組み合わせで協調して働いていることに他なりません。その意味では、無生物と比べて、生物は調節のモンスターである、と言うことが出来ます。
資料:嶋本伸雄
- mRNAのキャッピングとpolyAの付加
真核生物では、mRNAに一番最初に取り込まれるヌクレオチド(5'側と呼ぶ)に、キャッピング酵素によって、別の特殊な構造をしたヌクレオチドが付加されます。
真核生物の多くのmRNAや原核生物の一部のmRNAには、一番最後に取り込まれるヌクレオチド(3'側と呼ぶ)にアデニンが数十から数百個、専門の酵素によって付加されます。資料:嶋本伸雄
- mRNAのスプライシングと輸送
真核生物では、mRNAは直接合成されず、もっと長い前躯体の形で合成されることがあります。この余分な部分は、核の中で抜き取られ、mRNAの形に整形されます。これをスプライシングと呼びます。原核生物のRNAにも類似の現象があるので、もともと全生物にあったが、遺伝子の大きさを制限した方が有利な生物では、だんだん無くなっていったと通常考えられています。スプライシングを行う酵素の活性中心はRNAであり、太古のRNAワールドの名残と考えられています。
真核生物では、転写やスプライシングは核で起こりますが、mRNAの翻訳は、細胞質側で起こるので、出来上がったmRNAを核の外に輸送しなければなりません。専用の輸送路があり、輸送の能率を調節することが出来ます。資料:嶋本伸雄
- mRNAの分解
mRNAの量的調節は、転写調節による合成の速度だけでなく、分解の速度との両方によって決まります。合成しっぱなしでは、無限に蓄積し続けますし、一定のレベルに保つためや、必要なときに蓄積するためにも、分解は合成に劣らず必要なのです。
文責、資料:深川竜郎
- 翻訳とその調節
翻訳は、細胞質や小胞体に存在するリボソームという、数十個の蛋白質とRNAが集合した分子量が300-400万の巨大な分子機械によって行われます。転写の調節と同様に、mRNAに調節蛋白質がつくことによっても調節がなされます。またリボソームは、様々な調節因子の標的となっています。
翻訳は、通常3塩基を一つのアミノ酸に対応させるように起こります。この3塩基の組をコドンと言います。各アミノ酸は、tRNAに化学結合してリボソームに運ばれます。適切なアミノ酸を結合したtRNAは、その一部(アンチコドン)とmRNAのコドンとの結合により選ばれて、蛋白質に設計図の順番通り取り込まれます。
mRNAのどの部分から開始するかは、RNAの構造と開始コドン(ATGであることが多い)の位置で決まります。蛋白合成は、終止コドンが専用の蛋白質とリボソーム内で結合することで終了します。このアミノ酸を重合させる反応の活性中心もRNAであり、RNAワールドの名残と考えられます。資料:嶋本伸雄
- 蛋白質の折り畳みとプロセッシング
蛋白質が機能を発揮するためには、一定の形にならなければなりません。このためにもシャペロンと呼ばれる蛋白質やRNAが、翻訳途中や翻訳後に結合して、蛋白質の形を整えます。また、膜内に膜蛋白質が埋め込まれたりするときにもシャペロンは活躍するようです。
また、蛋白質にはRNAと同様に、長い前躯体の形で合成され、切断されて成熟するものがあります。また、糖やリピッドが化学的に結合される場合も有ります。このような蛋白質の修飾をプロセッシングと呼びます。資料:嶋本伸雄
- 蛋白質の輸送
蛋白質は、細胞質や小胞体で合成されますが、使用される場所は様々です。様々な輸送機構があり、場合によってはATPのエネルギーを利用して、適切な場所に送り込みます。
資料:嶋本伸雄
